9/18[1] 0.5Where we meet the p-value!
In this chapter will build on our previous exploration of estimation by considering the world of hypothesis testing. These are different but related ideas, and we’ll end the section showing why. Along the way we will introduce the p-value. We will do all this while considering binomial tests, which are some of the simplest data we will see.
Let’s start with an example. Klem Klem (1989) wanted to know if various factors (e.g., age, sex) of birds impacted the probability they would collide with glass windows. He collected data from several areas. In one of his samples, he found 18 purple finches collided with glass windows. 9 of these were in their hatching year (we’ll call them younger), and 9 were older. Is there any evidence that age impacts the probability of a purple finch colliding with the glass?
Notice we took a continuous variable here (age) and turned it into a categorical variable (younger and older). We can almost always due this but we lose some information (are the younger birds all 1 month old or nearly 1 year old?).

What have we done with data like this so far? You should know to calculate the proportion of each category impacting the probability of either category being represented in the sample. For example, since there were 9 older birds and 18 total, the proportion of older birds in the sample was:
9/18[1] 0.5We could also graph this, but it wouldn’t be very interesting:
library(ggplot2)
finch_data <- data.frame(age = c("younger", "older"), collisions = c(9,9))
ggplot(finch_data, aes (x=age, y = collisions))+
geom_col()+
labs(x="Age", y= "Collisions", title = "No apparent difference in sample based on age")
And although we haven’t discussed it, you should understand we could develop a confidence interval for this type of data (we’ll do so below). That would tell us the range of proportions we might typically expect. But does that really answer the question of whether age impacts likelihood of colliding with glass?
To answer that question, we have to move to hypothesis testing. This approach focuses on if a given value we found in the data (we’ll call it a signal) is really different (or significantly different) from what we would expect to see for a a given set of circumstances given the sampling error we now know to expect when we sample.
The given set of circumstances are described by a null hypothesis (this is why this approach is sometimes called NHST, or null hypothesis significance testing). We often abbreviate this as Ho. Let’s start by comparing this to estimation. Given our data, we could develop a 95% confidence interval (theoretically) that you should now understand will capture the true signal of the data about 95% of the time (here we are using proportion as opposed to mean, but it works). That’s a slightly different approach than asking if the true mean is equal to a given number, which is what hypothesis testing asks. Both deal with sampling error and explain why we can’t simply say an estimate being different than a given value proves there is a difference (make sure you understand why!).
For hypothesis testing in general, we again generate a known population that we draw from multiple times (should sound familiar), but this time the population parameters are set by a null hypothesis. Then we compare the spread of signals from those multiple draws (which exist due to sampling error!) to what we actually observed to determine how likely our draw was given the null hypothesis was true. If it’s unlikley to have occured by chance under the null hypothesis, we consider that evidence the null hypothesis is not correct and (eventually) reject it.
You can typically think of a null hypothesis as a hypothesis of no difference, affect, or relationship. Let’s walk through this with our bird example, where our null hypothesis would state age (measured as a category here!) has no impact on collisions. Given that, what would we expect to see in our sample?
This is a tricky question (that I chose on purpose!). Many approaches to this question start with a 50/50 expectation (like flipping a coin), but I’ve found that confuses students into thinking that is always the answer. Instead, think about what we would expect to see if age had no impact on collisions. We would not necessarily expect a 50/50 split in older and younger birds because that may not be what the population looks like. In fact, previous research has suggested the population is split closer to 3:1, with 3 younger birds for every older bird. This means if age has no impact on collisions, we should see about (due to sampling error!) 3 younger birds for every one older bird in our samples of birds that hit glass.
What did we actually see? We saw 9 younger birds and 9 older birds. That is not a 3:1 split, but its also a small sample size. If we had a population with a 3:1 split and randomly selected 18 birds from it, how rare would it be to get 9 younger and 9 older birds? That’ (close) to what we are asking.
In this case, our null hypothesis is comparing our signal to a set value. This is common when we measure a single group and want to compare it to something. So our null hypothesis could be written as conceptually as age does not impact the probabilty a bird collides with glass. However, its often better (in order to connect it to tests!) to write it using numbers. In this case, we could write
\[ H_O: p=.75 \]
where p is the probability of a bird in our sample being young (for a single draw), or what we expect on average over larger samples (a proportion!). Remember, to find a proportion, you count the number of samples that fall in a given group and divided that by the total number sampled. Alternatively, you can assign a score of 0 for values that are not in the focal group and a score of 1 to samples that are - the average of these scores will give you the proportion.
Note we could instead focus on old birds and get:
\[
H_O: p=.25
\]
We also have alternative hypotheses (abbreviated HA)to accompany each of these. Our alternative is just the opposite of the null. Together, they encompass all the probability space. It is usually just as simple as switching signs. For example, if we focus on younger birds, we get
\[ \begin{split} H_O: p=.75 \\ H_A: p \neq .75 \end{split} \]
The above ideas stay the same for all NHST approaches! We always use the null hypothesis to generate a “known” population (sometimes called the null population, draw samples from it, and then compare it to what we actually observed. What changes based on data type is how we generate the sample and multiple draws.
This example focuses on independent data points (one does not impact any others) that can be divided into 2 outcomes (young and old in our example). That is known as binomial data (so if data can be divided into two categories, we call it binomial data). A special case of binomial data exists when we only get one organism in our sample (e.g., one bird, one coin flip). We call this Bernoulli data.
For any type of data, we can simulate a distribution under the null hypothesis. For this example, we could put 4 pieces of paper in a hat, 3 labelled younger and 1 labelled older. We can then draw a sample of 18 (the number we actually observed) by drawing a piece of paper, writing down what it says, returning it to the hat, and repeating the process 9 more times to get single sample. For each sample, you could then calculate the observed proportion of younger birds. You could visualize the spread of those results using a histogram. It’s important to realize this is doable without a computer (think it through), but it would take a lot of time because you need a lot of samples (we’ll come back to this).
For now, let’s do it with the computer. Let’s also take a shortcut: Instead of younger and older, let’s label the pieces of paper 1 and 0. We will also call the 0’s failures and the 1’s successes. Then we can sum the draws and divide by 18 to get the proportion of successes (make sure you understand why!). For now, let’s do a 1000 random draws of 18.
set.seed(42)
choices <- c(rep(0,1),rep(1,3))
number_of_draws <- 18
number_of_simulations <- 1000
sampling_experiment<- data.frame("observed_proportion" = rep(NA, number_of_simulations))
for(i in 1:number_of_simulations){
sampling_experiment$observed_proportion[i] = sum(sample(choices,number_of_draws, replace=T))/number_of_draws
}Let’ s take a look at the first few draw
head(sampling_experiment$observed_proportion)[1] 0.6111111 0.7222222 0.8333333 0.8333333 0.6111111 0.7222222Note we see some variation. Also note it is impossible to get a proportion of .75. Why? We only sampled 18 individuals, so we can’t get any outcomes that aren’t some form of a whole number less than 18 divided by 18. This seems simple, but it’s a reminder that your signal being different than your hypothesized value is not sufficient to reject the null hypothesis!
Now let’s plot the proportions from our sampling experiment:
ggplot(sampling_experiment,
aes(x=observed_proportion)) +
geom_histogram(color="black") +
labs(title="Observed proportions from 1000 random draws",
x= "Proportion",
y= "Frequency")`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
Just looking at this, it seems getting a proportion of .5 is unlikely. It only occurred 14 times. However, we also need to note how often more extreme outcomes occurred. Why?
More extreme values (the same or further distance away from the hypothesized value as our observed signal were) are also useful in considering if the null hypothesis is valid. When we move to continuous distributions, it’s also impossible to get a certain value (as mentioned in the probability section).
In this example, our observed proportion was .5. That’s .25 away from the value under the null hypothesis (.75), so we should all simulations that were . 5 or less or 1 or more. That only happened 22 times. So, in taking 1000 random draws from our null population, we only saw what we actually observed (or something more extreme) 0.022% of the time.
sampling_experiment$Proportion = ifelse(sampling_experiment$observed_proportion <= .5,
'<= .5', ifelse(sampling_experiment$observed_proportion < 1, '>.5 & < 1', '>= 1'))
ggplot(sampling_experiment,
aes(x=observed_proportion, fill=Proportion)) +
geom_histogram(color="black") +
labs(title="Observed proportions from 1000 random draws",
x= "Proportion",
y= "Frequency")`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.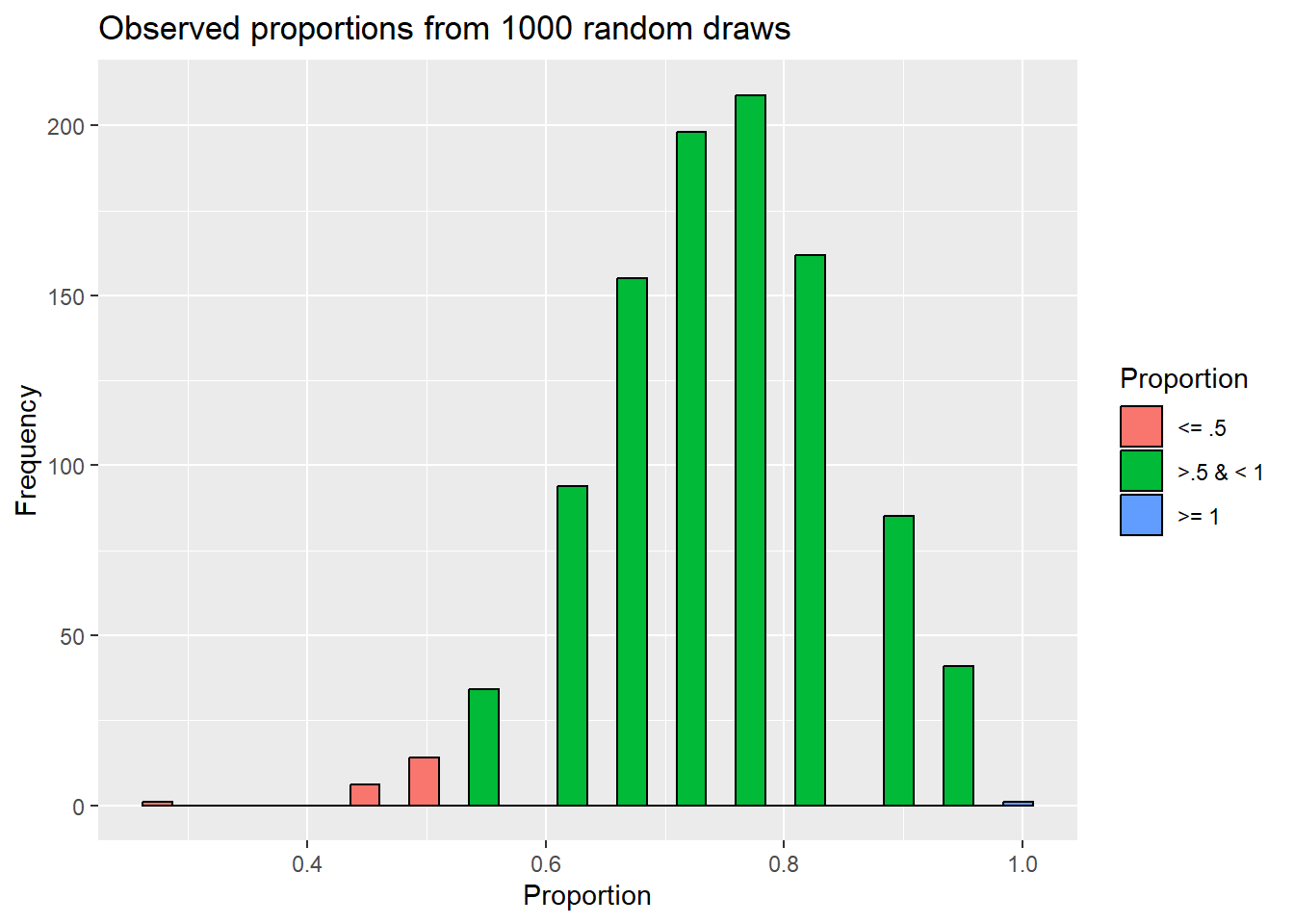
Or to think about as or more extreme..
sampling_experiment$Proportion2 = ifelse(abs(sampling_experiment$observed_proportion-.75) >= abs(9/18-.75), 'as or more extreme', 'not as or more extreme')
ggplot(sampling_experiment,
aes(x=observed_proportion, fill=Proportion2)) +
geom_histogram(color="black") +
labs(title="Observed proportions from 1000 random draws",
x= "Proportion",
y= "Frequency",
fill = "Proportion")`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
This is a p-value. Don’t get confused! We will get p-values from multiple tests, but the binomial distribution also has a p parameter (the proportion). They are not the same.
Explaining p-values is hard! You can see some statisticians try to explain the concept here.
A smaller p-value therefore means it is less likely to obtain your observed signal, or something more extreme, by chance when the null hypothesis is true. Traditionally, a p-value of less than .05 is thought to be sufficient evidence to reject the null hypothesis. This comparison value is sometimes called the \(\alpha\) (alpha), or significance, level. So if our p-value is < .05, we often say we have significant evidence against HO. While we now often get specific p-values from software, historically people used tables to find ranges (less than .05, for example).
Note our p-value is the probability we would get a signal like we observed by chance if the null hypothesis was true. This means for an \(\alpha\) of .05,we would expect to see something this extreme by chance 1 time out of 20! In other words, we can have errors. Think about it this way:
| Biological reality | ||
Decision (based on analysis of sample data) |
HO True | HO False |
| Reject HO | Type I error (P[ɑ]) | Power (1- \(\beta\) ) |
| Do not reject HO | Correct (P[1- ɑ]) | Type II Error ( Pr [\(\beta\)]) |
\(\alpha\) sets the limit we are ok with for rejecting HO when it is true (a Type 1 error). Alternatively, a Type II error is when we do not reject HO even when it’s is false. Importantly, \(\alpha + \beta \neq 1\)! Instead, \(\alpha + (1-\alpha)\) is the probability space for HO, and \(\beta + (1-\beta)\) (or \(\beta + power\)) is the probability space for HA. How they overlap depends on the signal, as the the distribution of signals under HA is close to what we already estimated for confidence intervals! You can visualize the relationship using the image below. Note the code is hidden given it’s length!
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.Warning: The `show_guide` argument of `layer()` is deprecated as of ggplot2 2.0.0.
ℹ Please use the `show.legend` argument instead.
The key point is the experimenter sets HO and \(\alpha\). Here we clearly see that in a typical test (like what we illustrated above) \(\alpha\) is split among the top and bottom of the distribution of signals under HO to create rejection regions. Note if we decrease \(\alpha\), which we can, we also decrease the power of the test! On a related note, we can return to an earlier image
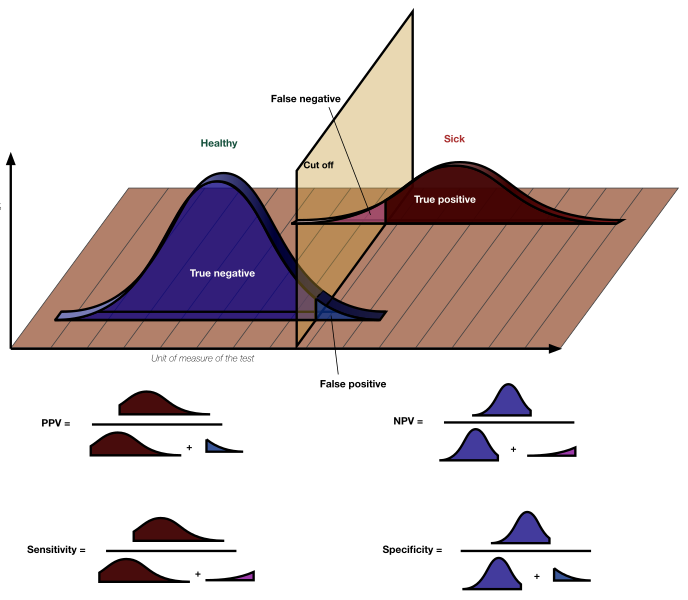
and note that power is equal to sensitivity!
These issues come up in power analysis, which is way of using prior estimates of the distribution of signals to determine appropriate sample sizes needed to detect significant results. Another form of power analysis occurs after a test is carried out, but this basically rehashing the p-value Levine and Ensom (2001) Heckman, Davis, and Crowson (2022).
This all points to a central idea of NHST. Larger sample sizes let you pick up smaller differences among groups! We will develop this below and consider relationships among significance and importance!
As shown above, we can always use simulations to obtain a p-value. However, without a computer (and even with) it’s cumbersome. We also have to redo it for every change (for example, what if our sample contained 19 instead of 18 birds?). Another option is to find an algorithm that can be used to calculate a distribution that is very close to what we saw with the simulation.
In the case of our binomial data, very close actually means exact. The binomial data is an example of data where we can fully describe the probability outcomes a sample may take. The binomial distribution allows calculations of how often you would expect s successes for a set number of trials (n-s) if a population had a proportion of p for the focal trait. This means we use the binomial distribution to calculate our probabilities.
Let’s not derive this fully, but just think about it. We have a proportion of success p, so (1 - p) is equal to the probability of failure (since we only have 2 options). For variance, we noted we find the average squared distance from the focal parameter value (in this case, a proportion).
For a single draw (what we call Bernoulli data), if we assume a success is equal to 1 and a failure to zero, we could “simply” multiply the likelihood of each our outcomes by their average squared distance from the mean
\[ \begin{split} \sigma^2 = (0-p)^2(1-p)+(1-p)^2(p)\\ which \ eventually \ reduces \ to \\ \sigma^2 =p(1-p) \end{split} \]
Since we are assuming each data point is independent ( remember the multiplication rule?), the probability distribution of getting S successes from N draws will be
\[ Pr[S] =p^S(1-p)^{N-S} \]
and the variance will be
\[ \sigma_\mu^2 =Np(1-p) \]
since when you add independent events, you multiply the variances.
Since we don’t care about the order of successes and failures in the sample, we have to think about combinations (not developed here), or how many ways one can arrange s successes in n draws. Putting it together, we can write the binomial distribution as
\[ P[n \ successes] = {n\choose s}p^s(1-p)^{n-s} \]
Using this distribution we can ask for the probability of obtaining any given number of successes for a given sample size. We can then find how likely we were to see a signal as more extreme than what we actually observed in the data by chance if the null hypothesis is true (p-value!). The dbinom function in R uses this distribution.
sum(dbinom(0:9,18,.75))+dbinom(18,18,.75)[1] 0.02498549This distributional assumptions also powers the binomial test (also called the exact binomial test). In R, we can use the binom.test function to carry it, with the arguments
x=number of successes
n = total number of trials
p= expected proportion under the null hypothesis
binom.test(x=9, n=18, p=.75)
Exact binomial test
data: 9 and 18
number of successes = 9, number of trials = 18, p-value = 0.02499
alternative hypothesis: true probability of success is not equal to 0.75
95 percent confidence interval:
0.2601906 0.7398094
sample estimates:
probability of success
0.5 Note for this test the default value for p is .5 (equal chance), so if you don’t enter it that’s what will be used.
Notice all our p-values are fairly close. P-values obtained using the distributional assumptions match exactly., and that obtained by simulation is very close. It should also be noted that although the p-value obtained by simulation will vary slightly each time, while those obtained using the binomial distribution will stay the same.
Now that we can “easily” run a binomial test, let’s do it a few times to see the impact of sample sizes. For example, we could see the same proportion/signal (50%) of younger birds in our sample, but if we only collected 8 individuals we would not be able to reject HO. Note what happens to our simulation outcomes:
number_of_draws <- 8
number_of_simulations <- 1000
sampling_experiment<- data.frame("observed_proportion" = rep(NA, number_of_simulations))
for(i in 1:number_of_simulations){
sampling_experiment$observed_proportion[i] = sum(sample(choices,number_of_draws, replace=T))/number_of_draws
}
sampling_experiment$Proportion = ifelse(sampling_experiment$observed_proportion <= .5,
'<= .5', ifelse(sampling_experiment$observed_proportion < 1, '>.5 & < 1', '>= 1'))
ggplot(sampling_experiment,
aes(x=observed_proportion, fill=Proportion)) +
geom_histogram(color="black") +
labs(title="Observed proportions from 1000 random draws",
x= "Proportion",
y= "Frequency")`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.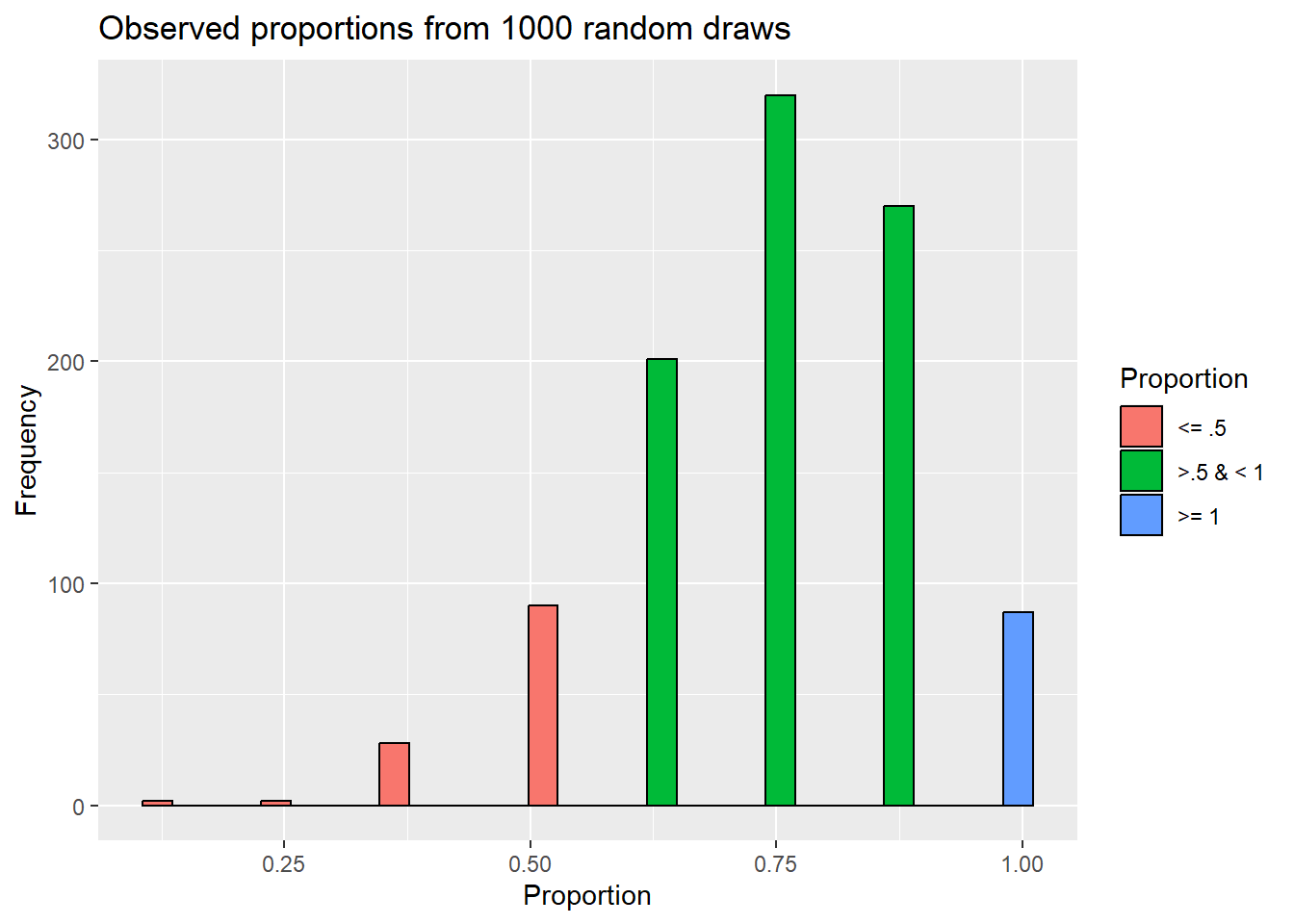
So now, we find that outcomes that are as or more extreme than what we saw in the actual data occur 2 times. So, in taking 1000 random draws from our null population, we only saw what we actually observed (or something more extreme) 0.002% of the time. Similarly,
binom.test(4,8,p=.75)
Exact binomial test
data: 4 and 8
number of successes = 4, number of trials = 8, p-value = 0.1138
alternative hypothesis: true probability of success is not equal to 0.75
95 percent confidence interval:
0.1570128 0.8429872
sample estimates:
probability of success
0.5 leads to a p-value which is >.05, so we fail to reject HO. Again, this relates to how sampling error interacts with sample size, much as we saw when constructing confidence intervals. This means we have to differentiate between statistical significance and importance.
Given a large enough sample size, we can detect very small differences from our parameter value under the null hypothesis. For example, what if data from another population of finches showed 780 younger birds out of a sample of 1000 birds that collided with windows. If we assume the population distribution in regards to age is the same, we are still testing
\[ \begin{split} H_O: p=.75 \\ H_A: p \neq .75 \end{split} \]
In our sample, we found a signal of 0.78, which is very close to .75. However, we find a p-value of
binom.test(780,1000, p = .75)
Exact binomial test
data: 780 and 1000
number of successes = 780, number of trials = 1000, p-value = 0.02843
alternative hypothesis: true probability of success is not equal to 0.75
95 percent confidence interval:
0.7530202 0.8053200
sample estimates:
probability of success
0.78 Is the slight increase in older birds really important to understanding the population? Maybe, or maybe not. The point is we have to understand the difference between estimates and significance and the more nebulous idea of importance.
This is one way estimates and NHST work together. Estimate focuses on the sample (Given sampling error, where do we think true parameter lies?). Hypothesis testing focuses on the likelihood of the signal given the null distribution (how likely were we to observe data that we did, a la the p-value), but gives no information about the actual difference (which could be important for determining if something really matters!).
In introducing the p-value (and estimation) we focused on two-sided (or two-tailed) tests. This means we considered deviations from our value under the null hypothesis (for p-values) or via sampling error (for confidence intervals) based on their magnitude, and not direction. However, we can instead decide we want to consider differences to one “side” of our value of interest. Following this idea, we have 3 options for our null and alternative hypotheses (note C is a constant value here!):
t ypical)** |
Focused on signals greater than predicted in null | Focused on signals less than predicted in null | |
| HO | p = C | p <= C | p >= C |
| HA | p \(\neq\) C | p > C | p < C |
For example, Claramunt et al Claramunt, Hong, and Bravo (2022) wished to consider if roads impaired bird movement. To do they considered if banded birds were more likely to be recapture in one of 3 areas across a road from their original location or one of 6 on the same side on which they were captured. They were only interested if roads reduced bird movement, so they were justified in using a sided test. These tests move all the rejection region to one side. You can run these by adding an alternative argument to binom.test
binom.test(116,641, p=.33, alternative = "less")
Exact binomial test
data: 116 and 641
number of successes = 116, number of trials = 641, p-value < 2.2e-16
alternative hypothesis: true probability of success is less than 0.33
95 percent confidence interval:
0.0000000 0.2078378
sample estimates:
probability of success
0.1809672 Here we reject HO, where
\[ \begin{split} H_O: p>=.33 \\ H_A: p < .33 \end{split} \]
However, sided or tailed tests should be rarely used? Why? Because it can be too tempting to use a sided test after observing the data! A signal that is not significant at the \(\alpha\) =.05 level using two-sided tests can be significant as a one-tailed test.
If you do use these, note they correspond to confidence bounds instead of intervals. Again, the full rejection region is placed on one side of the estimate.
Let’s return to our bird collision example and connect estimation and p-values (and teach you how to estimate confidence intervals for binomial data).
Remember, we found 9 younger birds in our sample of 18. This means our estimate for the proportion of younger birds is 0.5. Just like for continuous data, we can consider sampling error in our estimate. Let’s think about how that might happen.
In short, the standard error of p is
\[ SE(p) = \sqrt{\frac{p(1-p)}{N}} \]
but since we don’t know p, we use our estimate
\[ SE(\hat{p}) = \sqrt{\frac{(\hat{p}(1-\hat{p})}{N}} \]
To find out a little more, click here.
For a single draw (Bernoulli data), if we assume a success is equal to 1 and a failure to zero, we could “simply” multiply the likelihood of each our outcomes by their average squared distance from the mean
\[ \begin{split} \sigma^2 = (0-p)^2(1-p)+(1-p)^2(p)\\ which \ eventually \ reduces \ to \\ \sigma^2 =p(1-p) \end{split} \]
If we move to N independent draws, we predict the average observed outcome (or the mean number of successes!) will be
\[ \mu_S = Np \]
Since we are assuming each data point is independent, the variance of N draws will be
\[ \sigma_\mu^2 =Np(1-p) \]
so
\[ \sigma_\mu =\sqrt{Np(1-p)} \]
Notice in doing this we went from a proportion to a number of successes! Now we can use our typical equation for standard error of the means
\[ [\sigma_{\mu_s} = \frac{\sigma}{\sqrt{N}} = \frac{\sqrt{(Np(1-p)}}{\sqrt{N}} = \sqrt{\frac{(p(1-p)}{N}} \ ] \sim [s_{\overline{Y}} = \frac{s}{\sqrt{N}} = \frac{\sqrt{(N\hat{p}(1-\hat{p})}}{\sqrt{N}} = \sqrt{\frac{(\hat{p}(1-\hat{p})}{N}}] \]
This is actually a bit tricky as it assumes some connections between categorical and continuous data, and many ways have been proposed to do this (Subedi and Issos 2019), but this gets us close.
It turns out our estimate of the standard error may be biased, especially for small sample sizes or extreme (close to 0 or 1) values of p. For that reason, several ways have been suggested to calculate confidence intervals (Subedi and Issos 2019) . Note, for example, the binom.confint function in the binom package gives multiple outcomes. For the function,
the first argument is the number of successes
the second argument is the number of trials
library(binom)
binom.confint(9,18) method x n mean lower upper
1 agresti-coull 9 18 0.5 0.2903102 0.7096898
2 asymptotic 9 18 0.5 0.2690160 0.7309840
3 bayes 9 18 0.5 0.2835712 0.7164288
4 cloglog 9 18 0.5 0.2592888 0.7005143
5 exact 9 18 0.5 0.2601906 0.7398094
6 logit 9 18 0.5 0.2841566 0.7158434
7 probit 9 18 0.5 0.2812976 0.7187024
8 profile 9 18 0.5 0.2808406 0.7191594
9 lrt 9 18 0.5 0.2808092 0.7191908
10 prop.test 9 18 0.5 0.2903102 0.7096898
11 wilson 9 18 0.5 0.2903102 0.7096898For now, we will use method labelled the Agresti-Coull method, which adjusts for slight bias in other estimates and is useful across sample sizes.
using_distribution <- dbinom(0:18,18,.75)
finches <- data.frame (Number = 0:18, Probability = using_distribution)
finches$Proportion <- finches$Number/18
finches$criteria <- "retain"
finches$criteria[pbinom(finches$Number, 18, .75) < .025] <- "reject"
finches$criteria[(1-pbinom(finches$Number, 18, .75)) < .025] <- "reject"
proportion_observed = data.frame(Proportion = 9/18, Probability = .15)#sets height
ggplot(finches, aes(x = Proportion, y = Probability)) +
geom_bar(stat="identity", aes(fill = criteria)) +
geom_segment(x = .29031, xend = .70968,y= .15 , yend =.15) +
geom_vline(xintercept = .75, color = "blue") + geom_vline(xintercept = 9/18, color = "black") +
geom_point(data= proportion_observed) +
ggtitle("Comparing p-values and confidence intervals for finch problem")
Note we see our rejection region in red; it also contains our estimate! Similarly, the 95% confidence interval for our estimate does not contain the paramater value under the null hypothesis!
Make sure you understand the above concepts (i.e., how p-values are is related to null hypotheses and how to interpret them!). Our following chapters will extend this idea to different types of data, starting with continuous data from a single sample in the next chapter.